Is Your Language Holding Back Your AI Agent? How Language Resources Affect LLM Performance

Large Language Models (LLMs) have revolutionized every day tasks and become a part of our day to day life, demonstrating remarkable capabilities across a range of activities. However, their performance often varies depending on the language we're using. This can have significant implications for their deployment in multilingual settings, especially when extending support to low-resource languages.
High-Resource and Low-Resource Languages
Languages are broadly classified based on the amount of training data available at the time of training LLMs. High-resource languages, such as English, Chinese, and Spanish, benefit from vast amounts of text data, which facilitates the creation of uniform and well-structured embedding spaces. These embeddings, which represent the semantic relationships between words, phrases, and concepts, tend to be more consistent and stable in high-resource languages. This uniformity ensures that LLMs perform reliably across a variety of tasks for these languages.
Conversely, low-resource languages face a different reality. Due to the limited availability of high-quality data, the embedding spaces for these languages are often sparse and less uniform. This inconsistency can lead to subpar performance, as the model struggles to capture nuanced semantic relationships. For instance, tasks like sentiment analysis, machine translation, or question answering may yield less accurate results when applied to low-resource languages.
In simpler terms we can think of these like talking to a wise old person who has a lot of life experiences (a high-resource language) versus talking to a little kid who has not lived much yet (low-resource language). Of course, the wise old person who has had many experiences in life is better equipped to give you advice. They will be able to better understand your emotions and relate to them, leading to better advice.
Why Does This Happen?
The training process of LLMs inherently favors languages with more data. High-resource languages dominate the loss optimization during training, leading to embedding spaces that are better tuned to these languages. On the other hand, low-resource languages are often underrepresented, resulting in embedding spaces that are:
- Less densely populated: Fewer examples mean weaker representation of linguistic nuances.
- More prone to noise: The lack of data increases the likelihood of overfitting or spurious correlations.
- Poorly aligned with high-resource languages: This misalignment can cause inaccuracies in multilingual tasks, such as translation or cross-lingual understanding.
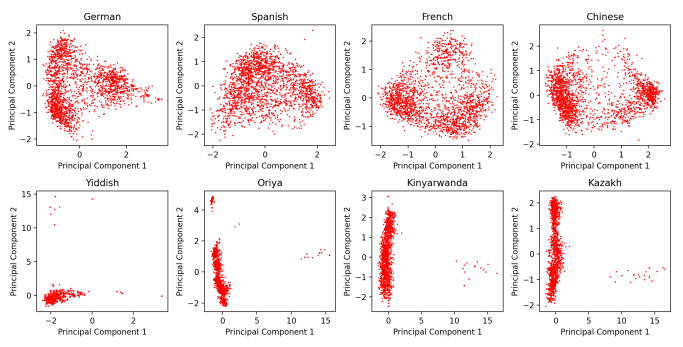
Here we can see what happens with these embedding spaces of Gemma 7B with 8 different languages. Can you tell which ones are high-resource and which ones are low-resource languages?
Correcting the Imbalance: The Role of Fine-Tuning
Recent advancements in LLM development, such as the Qwen models, demonstrate how fine-tuning can mitigate these issues. Fine-tuning involves training a pre-trained model on specific data tailored to the target language or task. This additional training can help align the embedding spaces of low-resource languages with their high-resource counterparts. Here’s how:
- Data Augmentation: By introducing synthetic or curated datasets for low-resource languages, fine-tuning enriches the embedding space.
- Multilingual Alignment: Techniques like contrastive learning can align representations across languages, improving performance in cross-lingual tasks.
- Task-Specific Optimization: Fine-tuning on task-relevant data ensures that the model’s performance improves for specific applications, even in low-resource settings.
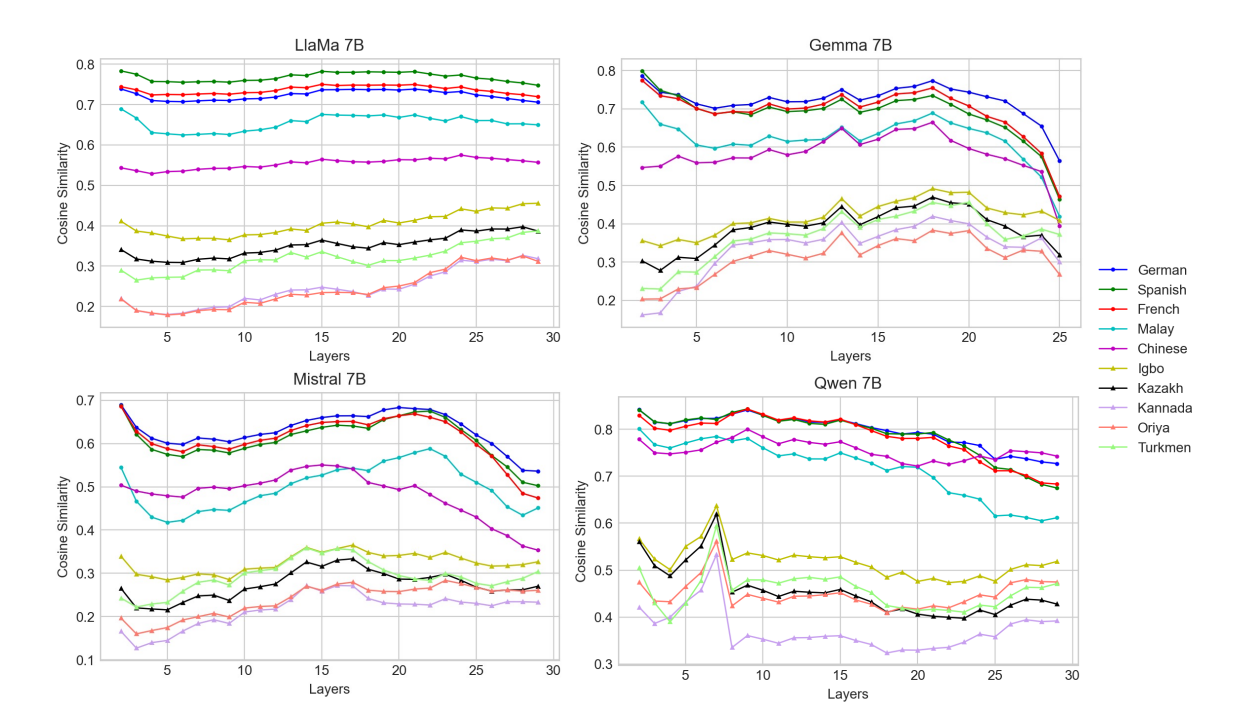
These graphs show the similarity to English performance across layers in the LLM for a couple different models. Notice how in the Qwen model, Chinese is the only high-resource language that shows an improvement in performance over the last layers. This is thanks to their fine-tuning work specifically for Chinese training data.
Running Some Tests
We ran some tests comparing English and Spanish performance using our very own Agent Quality Studio.
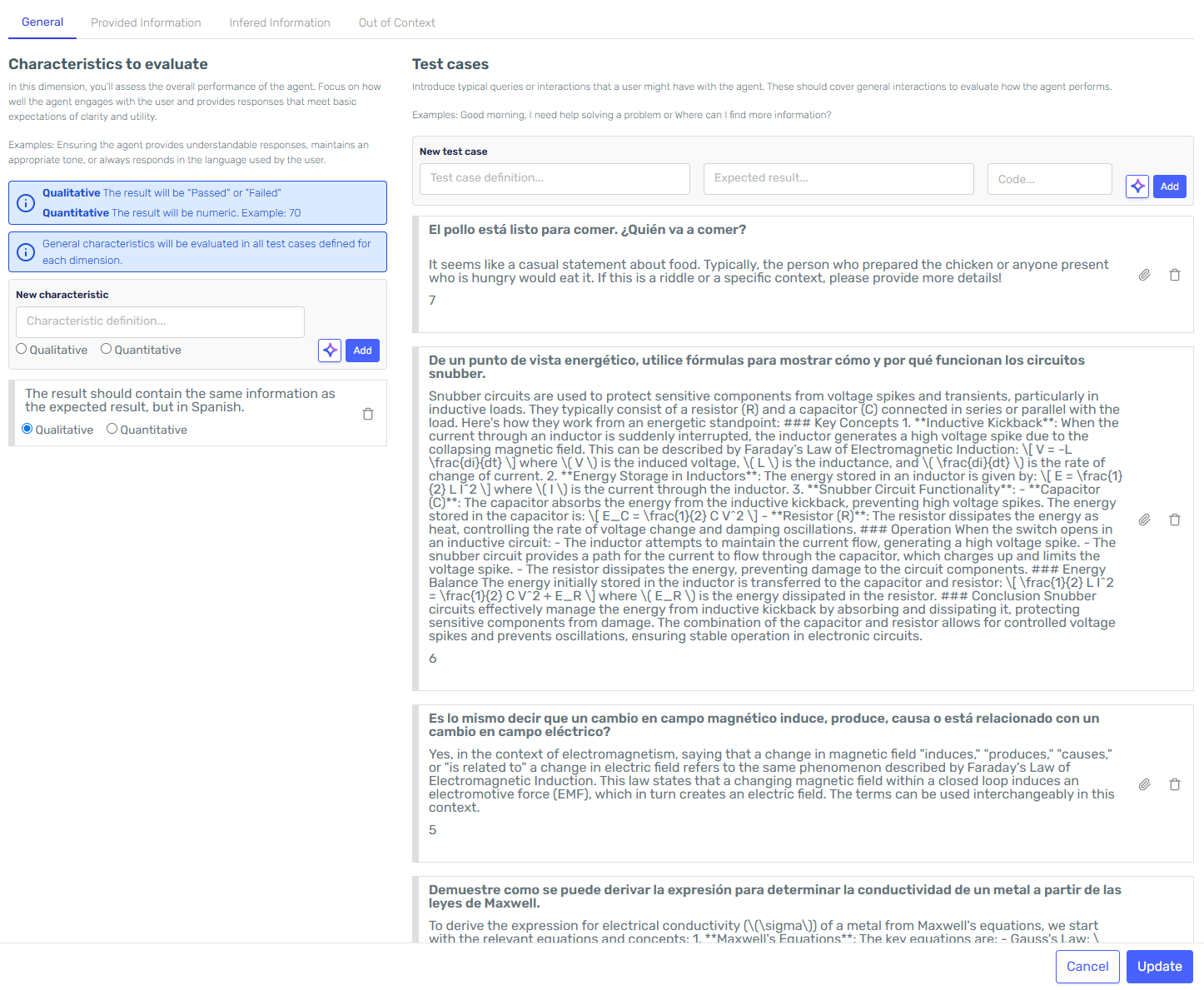
We asked some very specific and challenging questions in both English and Spanish and had automated testing determine whether they were similar enough. Note that in this testing we take English as absolutely correct in the sense that we don't measure performance as how correct an answer is, rather as how similar it is to the English answer. In some cases it could not be the case that the English answer itself is sub-optimal. We just measure similarity to English as that is the standard among LLMs.
Both models got every question correct except for one interesting case where the Spanish model did even better! Though this may be due to the connotation some specific words may have in Spanish.

Final Thoughts
We learned that low-resource languages can lead to non-uniform embedding spaces and this has a significant negative impact on LLM performance. However, as we could see in our test results it's really not a big deal among high-resouce languages, even in challenging topics like STEM. How does this really affect day-to-day operation with LLMs? It will really depend on your use case but, generally speaking, as long as you stay within high-resource languages you honestly don't have much to worry about. So, here's what you need to keep in mind in order to get the most out of your AI Agents:
- Try to stick to high-resource languages if possible. Sticking to English, Spanish, French, Chinese, etc... will yield better results across the board
- If you really need to squeeze out the best performance you can for a specific language then consider fine-tuning. As we saw previously, this can greatly help with performance in a specific language.